In order to understand Kubernetes, you first must understand containers. If you're already familiar with containers and using Docker, feel free to skip to the part of this document that introduces Kubernetes.
Containers are isolated environments that exist to run a specific application. "Isolated" here means they have:
- their own separate root file system
- their own separate processes
- their own separate memory
- their own separate network ports
- their own separate environment variables
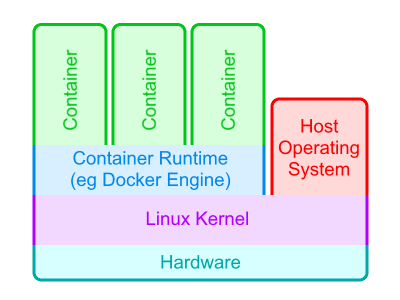
It may then sound like containers are virtual machines. It may be helpful at first to think of them as virtual machines (VMs), if it helps you understand the idea. Like VMs, they live on a host machine. Also like VMs, containers can't under normal circumstances access the host's files or environment. The host in effect limits what the container can see.
But containers are not VMs. Containers can only be run on Linux hosts, and they make direct use of the host's Linux kernel. VMs instead have to virtualize this, and so VMs have a lot more overhead than containers.
As mentioned above, containers are meant to run a specific application. A common use case is a microservice. A container with a Java microservice would have the JAR built for that service. A container meant for Python will have the virtual environment on it as well as the Python script files. If you have two microservices that need to communicate with each other, then each microservice will be run in their own separate containers. Containers can also be used to deploy such things as:
- web servers serving HTML pages
- reverse proxies
- databases, such as MongoDB
Containers as a technology are independent of Kubernetes and have been used since before Kubernetes. They often appear even in projects that don't make use of Kubernetes.
There exist many kinds of containers, but Docker containers are by far the most common and are what this document will focus on. You'll almost certainly never need to use any other kind of container than Docker for the foreseeable future.